![Hacking Any Website [part - 2]](https://cdn.hashnode.com/res/hashnode/image/upload/v1654246178186/8gzD4YTnt.jpeg?w=1600&h=840&fit=crop&crop=entropy&auto=compress,format&format=webp)


What are we looking for?
Content can be many things, a file, video, picture, backup, a website feature. When we talk about content discovery, it’s the things that aren’t immediately presented to us and that weren’t always intended for public access.
This content could be, for example, pages or portals intended for staff usage, older versions of the website, backup files, configuration files, administration panels, etc.
These contents can be discovered manually, using some kind of automation and using OSINT. Each has it’s merits and demerits.
Manual Discovery
Robots.txt: A Robots. txt file tells search engine crawlers which urls the crawler can access on your site or can’t access. Iif you’ve ever used a crawler, you might know its kind of useless. crawlers can be set to ignore robots.txt completely. moreover, they hand out exactly the kind of information, we as hackers are looking for on a silver platter. you can access robots.txt simply by adding that to your url path. for example, ]{website}/robots.txt
Favicon: A favicon is a graphic image (icon) associated with a particular Web page and/or Websites. Many recent user agents (such as graphical browser's and newsreaders) display them as a visual reminder of the Web site identity in the address bar or in tabs. Sometimes when frameworks are used to build a website and if the website developer doesn’t replace this with a custom one, this can give us a clue on what framework is in use. OWASP hosts a database of common framework icons that you can use to check against the target’s favicon OWASP’s favicon databased. Once we know the framework stack, we can use external resources to discover more about it.
Sitemap.xml: An XML Sitemap is a special document which lists all pages on a website to provide search engines with an overview of all the available content. These can sometimes contain areas of the website that are a bit more difficult to navigate to or even list some old webpages that the current site no longer uses but are still working behind the scenes
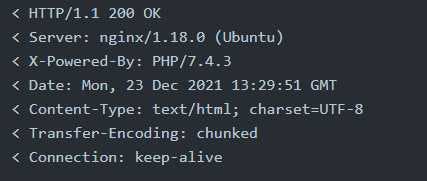
HTTP Headers: HTTP headers let the client and the server pass Additional information with an HTTP request or response. When we make requests to the web server, the server returns various HTTP headers. These headers can contain useful information such as the webserver software and possibly the programming/scripting language in use.
OSINT Discovery
OSINT is an information that can be accessed without speciaHTTP responselist skills or tools. The Central Intelligence Agency says that OSINT includes information gathered from the internet, mass media, specialist journals and research, photos, and geospatial information. For example, Viewing someone’s public profile on social media is OSINT; OSINT is also information drawn from non-classified sources.
Wappalyzer: Wappalyzer (wappalyzer.com) is an online tool and browser extension that helps identify the versions, what technologies a website uses, such as frameworks, Content Management Systems (CMS), payment processors and much more.
GitHub: GitHub is a version control system that tracks changes to files in a project. When users have finished making their changes, they commit them with a message. Repositories can either be set to public or private and have various access controls. You can use GitHub’s search feature to look for company names or website names to try and locate repositories belonging to your target. Once discovered, you may have access to source code, passwords or other content that shouldn’t be made public
Cloud Storage: buckets are a storage service provided by cloud services, allowing people to save files and even static website content in the cloud accessible over http and https. the owner of the files can set access permissions to either make files public, private and even writable. sometimes these access permissions are incorrectly set and inadvertently allow access to files that shouldn’t be available to the public. for example, the format of the s3 buckets is https://{name}.s3.amazonaws.com where {name} is decided by the owner, s3 buckets can be discovered in many ways, such as finding the urls in the website’s page source, github repositories or automating processes
and countless other resources….
Automatic Discovery
What is Automated Discovery?: Automated discovery is the process of using tools to discover content rather than doing it manually. This process is automated as it usually contains hundreds, thousands or even millions of requests to a web server. These requests check whether a file or directory exists on a website, giving us access to resources we didn’t previously know existed. This process is made possible by using a resource called wordlists. Wordlists are just text files that contain a long list of commonly used words; they can cover many different use cases. For example, a password wordlist would include the most frequently used passwords, whereas we’re looking for content in our case, so we’d require a list containing the most commonly used directory and file names. An excellent resource for wordlists that is github.com/danielmiessler/SecLists